I enjoyed seeing this image in an article in The Register.
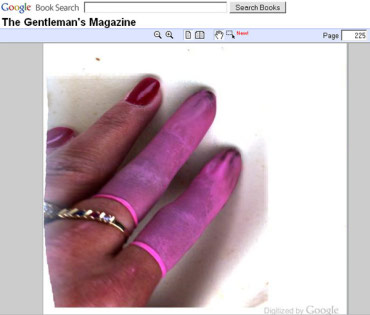
The picture is a screen shot from Google Books viewing a page from a 1855 issue of The Gentleman’s Magazine. The latex-clad fingers belong to one of the people whose job it is to scan the books for Google’s book project.
Information technologies often hide the processes that bring us the information we interact with. Revealing errors give a picture of what these processes look like or involve. In an extremely literal way, this error shows us just such a picture.
We can learn quite a lot from this image. For example, since the fingers are not pressed against glass, we might conclude that Google is not using a traditional flatbed scanner. Instead, it is likely that they are using a system similar to the one that the the Internet Archive has built that is designed specifically for scanning books.
But perhaps the most important thing that this error reveals is something we know, but often take for granted — the human involved in the process.
The decision on where to automate a process, and where leave it up to a human, is sometimes a very complicated one. Human involvement in a process can prevent and catch many types of errors but can cause new ones. Both choices introduce risks and benefits. For example, an automated bank transaction system may allow human to catch obvious errors and to detect suspicious use that a computer without “common sense” might miss. On the other hand, a human banker might commit fraud to try to enrich themselves with others money — something a machine would never do.
In our interaction with technological systems, we rarely reflect on the fact, and the ways, that the presence of humans in these areas is important to determining the behavior, quality, reliability, and the nature and degree of trust that we have in a technology.
In our interactions with complex processes through simple and abstract user interfaces, it is often only through errors — distinctly human errors, if not usually quite as clearly human as this one — that information workers’ important presence is revealed.
“this errors shows us” –> “this error shows us”
Thanks Trevor. It’s fixed.
Perhaps also of interest, Google now has (had?) a ‘this page is unreadable’ link which you can submit to let them know that a page is unreadable. No idea if they then actually go back and rescan things; I guess I’ll keep an eye on that link to see.
Another example showed up here: http://kottke.org/09/10/googles-page-turners
Looks like a different person with the same pink finger condoms.
Perhaps also of interest, Google now has (had?) a ‘this page is unreadable’ link which you can submit to let them know that a page is unreadable. No idea if they then actually go back and rescan things; I guess I’ll keep an eye on that link to see.