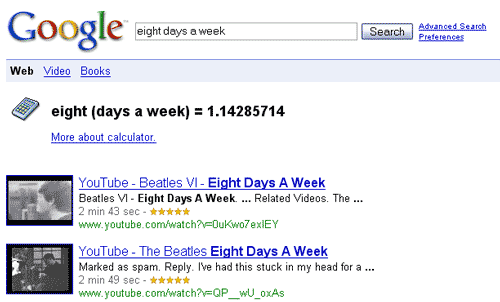
A while ago, Mark Pilgrim wrote about being prompted with a license agreement that looked like this.
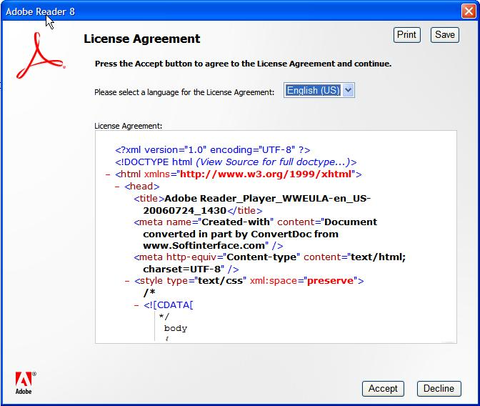
If, like most people, you have trouble parsing the agreement, that’s because it’s not the text of the license agreement that’s being shown but the “marked up” XHTML code. Of course, users are only supposed to see the processed output of the code and not the code itself. Something went wrong here and Mark was shown everything. The result is useless.
Conceptually, computer science can be boiled down to a process of abstraction. In an introductory undergraduate computer science course, students are first taught syntax or the mechanics of writing code that computers can understand. After that, they are taught abstraction. They’ll continue to be taught abstraction, in one way or another, until they graduate. In this sense, programming is just a process of taking complex tasks and then hiding — abstracting — that complexity behind a simplified set of interfaces. Then, programmers build increasingly complex tools on top of these interfaces and the whole cycle repeats. Through this process of abstracting abstractions, programmers build up systems of almost unfathomable complexity. The work of any individual programmer becomes like a tiny cog in a massive, intricate machine.
Mark’s error is interesting because it shows a ruptured black box — an accute failure of abstraction. Of course, many errors, like the dialog shown below, show us very little about the software we’re using.
With errors like Mark’s, however, users are quite literally presented with a view of parts of the system that programmer was trying to hide.
Here’s another photo I’ve been showing in a my talks that shows a crashed ATM displaying bits of the source code of the application running on the ATM; a bit of unintentional “open sourcing.”
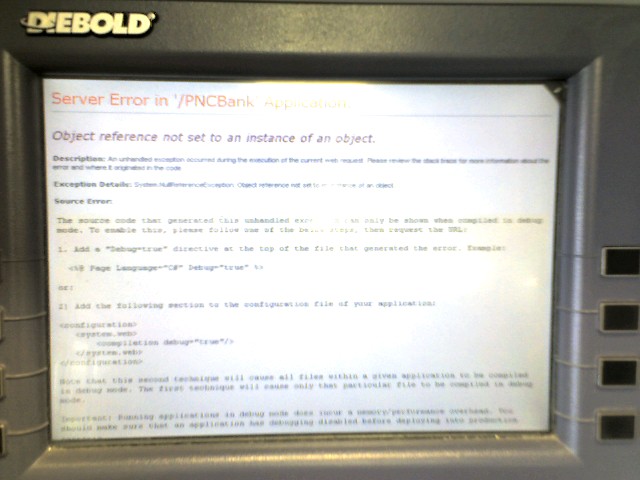
These examples are embarrassing for authors of the software that caused them but are reasonably harmless. Sometimes, however, the window we get into a broken black box can be shocking.
In talks, I’ve mentioned a configuration error on Facebook that resulted in the accidental publication of the Facebook source code. Apparently, people looking at the code found little pieces like these (comments, written by Facebook’s authors, are bolded):
$monitor = array( '42107457' => 1, '9359890' => 1);
// Put baddies (hotties?) in here/* Monitoring these people's profile viewage.
Stored in central db on profile_views.
Helpful for law enforcement to monitor stalkers and stalkees. */
The first block describes a list of “baddies” and “hotties” represented by user ID numbers that Facebook’s authors have singled out for monitoring. The second stanza should be self-explanatory.
Facebook has since taken steps to avoid future errors like this. As a result, we’re much less likely to get further views into their code. Of course, we have every reason to believe that this code, or other code like it, still runs on Facebook. Of course, as long as Facebook’s black box works better than it has in the past, we may never again know exactly what’s going on.
Like Facebook’s authors, many technologists don’t want us knowing what our technology is doing. Sometimes, like Facebook, for good reason: the technology we use is doing things that we would be shocked and unhappy to hear about it. Errors like these provide a view into some of what we might be missing and reasons to be discomforted by the fact that technologists work so hard to keep us in the dark.