One set of errors that almost everyone has seen — even if they don’t know it — involve the failure of a very common process in computer programming called interpolation. While they look quite different, both of the following errors — each taken from the Daily WTF’s Error’d Series — represent an error whose source would be obvious to most computer programmers.

The term interpolation, of course, is not unique to programmers. It is a much older term that was historically used to describe errors in hand-copied documents. Interpolation in a manuscript refers to text not written by an original author that was inserted over time — either through nefarious adulteration or just by accident. As texts were copied by hand, this type of error ended up happening quite frequently! In its article on manuscript interpolation, Wikipedia describes one way that these errors occurred:
If a scribe made an error when copying a text and omitted some lines, he would have tended to include the omitted material in the margin. However, margin notes made by readers are present in almost all manuscripts. Therefore a different scribe seeking to produce a copy of the manuscript perhaps many years later could find it very difficult to determine whether a margin note was an omission made by the previous scribe (which should be included in the text), or simply a note made by a reader (which should be ignored or kept in the margin).
But while manuscript interpolation described a type of error, interpolation in computer programming refers to a type of text swapping that is fully intentional.
Computer interpolation happens when computers create customized and contextualized messages — and they do so constantly. Whereas a newspaper or a book will be the same for each of its readers, computers create custom pages designed for each user — you see these all the time as most messages that computers print are, in some way, dynamic. In many cases, these dynamic messages are created through a process called string or variable interpolation. For those who are unfamiliar with the process, an explanation of the errors above can reveal the details.
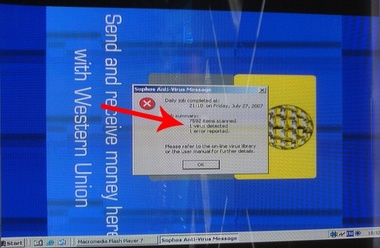
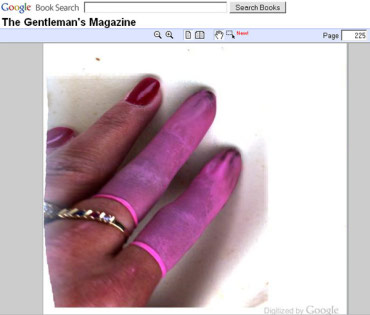
In the first example, the receipt read (emphasis mine):
You Saved a total of {@Total-Tkt-Discount} off list prices.
In fact, the computer is supposed to swap out the phrase {@Total-Tkt-Discount} for the value of a variable called Total-Tkt-Discount. The {@SOMETHING} syntax is one programming language’s way of signifying to the computer, “take the variable called SOMETHING and use its value in this string instead of the everything between (and including) the curly braces.” Of course, something didn’t quite work right and the unprocessed — or uninterpolated — text was spit out instead. With this error, the computer program that is supposed to be computing our ticket price was revealed. Additionally, we have a glimpse into the program, its variable names, and even its programming language.
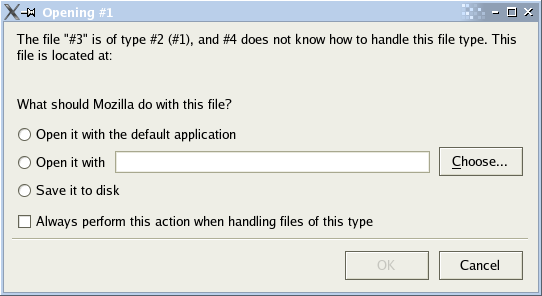
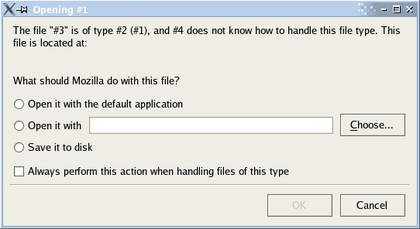
The second error from a (not very helpful) dialog box in Mozilla Firefox is a more complicated but fundamentally similar example (emphasis mine):
The file “#3” is of type #2 (#1), and #4 does not know how to handle this file type.
The numbers, in this case, reflect a series of variables. The dialog is supposed to be passed a list of values including the file name (#3), the file type (#2 and #1), and the name of the program that is trying to open it (#4). This list is supposed to be swapped in from placeholder values — interpolated — before any user sees it. Again, something went wrong here and a user was presented with the empty template that only the programmer and the program are ever supposed to see.
Nearly every message a computer or a computerized system presents us will be processed and interpolated in this way. In this sense, computer programs act as powerful intermediaries processing and displaying data. Perhaps more importantly, interpolation reveals just how limited computers’ expression really is. These messages are not more complicated than simple fill-in-the-blank messages. Simple as they may be, they are entirely typical of the way that computers communicate with us.
From a user’s perspective, it’s easy to imagine sophisticated systems creating and presenting highly dynamic messages to us — or to simply not think about it at all. In reality, few computer programs’ ability to communicate with us is more sophisticated than a game of Mad Libs. The simplicity of these systems, the limitations that they impose on what computers can and can’t say, and the limitations they place on we can and can’t say with computers, are revealed through these simple, common, interpolation errors. To understand all of this, we need only recognize these errors and reflect on what they might reveal.